最近下载了点资料,学了学Android,发现Android入门还算简单,从.NET过渡到Android,也就三七十一天的事。
大伙有空也可以学学。。。
好了,言归正文,那日,有网友发了一个他们公司的数据层框架的DLL,让我审视(Reflector查看如下):

炸一看框架,支持的数据库种类繁多,看来写框架的人涉及面还挺广的。
往里一看,比较悲催,有广度而无深度,另外数据库种类的dll需要提前引用,那是相当浩大的数据库工程:

框架具体就不过多点评了,在不经意思间,本人看到有一个闪光点,觉的可以和大伙分享分享:
1:检测某列是否存在:

2:检测某表是否存在:

这是一条判断某字段列和某表是否存在的方法,此处用了select X from table的方式,然后调用了GetSingle(sql)。
而 GetSingle的代码如下:

代码里,关于ADO.net的相关对象没提升到全局变量以重用这个不是讲的重点,就先忽略先,今天分享的知识点是ExecuteScalar:
对于ADO.NET的Command命令,有三个方法,大伙很熟悉:
1:ExecuteDataReader,返回数据流,用于列表读取。 2:ExecuteScalar,返回首行首列。 3:ExecuteNonQuery,返回首影响的行。
解说:
如果我们从语义上讲,用ExecuteScalar执行一条select * from table,只返回首行首列,看似还过的去,然实际不然。 实际上,后面的ExecuteScalar,或是ExecuteNonQuery,内部都是调用的ExecuteDataReader来处理的,见如下代码即知:
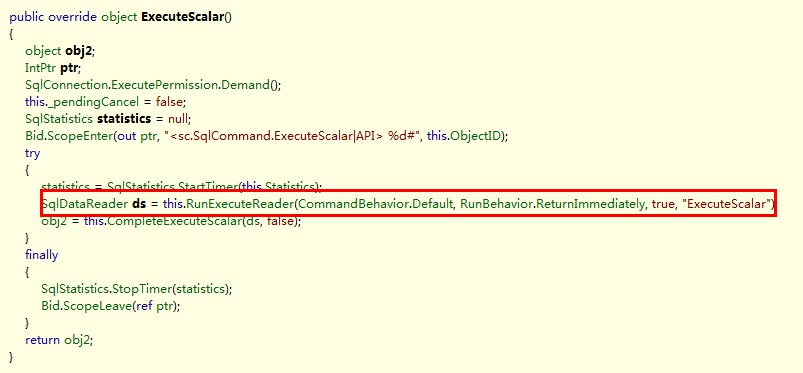
说明分析:
微软并没有什么特殊照顾,所以原来的语句,仍会到数据库里,按语句的要求,并找出全部满足条件的数据流进行返回。 当然,值的欣慰的是,DataReader是一个流数据传输,它并不是一次性传输所有数据,而是部分段传输。
中间我做了一个小测试,大体过程是这样的:
使用DataReader去读取数据返回一个SqlDataReader,然后断点,接着把数据库服务给停了,然后继续调试,发现数据还可以正常读取。 说明还未读取之时,部分数据就先通过管道把数据从数据库传输到程序的内存中了,后来按F5继续,读取后面就会抛进程管道已关闭的错误。
总结:
本文说明两点使用方法上的两点:
1: 本来是Top 1 的语句,结果变成Select *,这两条语句在数据库端执行,性能的差异不说大伙也懂了。 2: ExecuteScalar虽然是返回首行首列,但实际返回的是个DataReader,如果你查询的是列表,实际上内存传输了列表,只是最终你程序读取了列表中的第一个字节。 当然了,由于流的传输,并不一次性传输全部,只是部分段传输,所以性能的损失并不是太明显。
要写好底层框架,任重而道远,望大伙再接再励。